Blogg
Här finns tekniska artiklar, presentationer och nyheter om arkitektur och systemutveckling. Håll dig uppdaterad, följ oss på LinkedIn
Här finns tekniska artiklar, presentationer och nyheter om arkitektur och systemutveckling. Håll dig uppdaterad, följ oss på LinkedIn

How do you approach using Kafka to store your data when building a HTTP api? In this series we build an application which would traditionally be backed by a classic database, the basic ‘Create-Read-Update-Delete’ api. Instead of a traditional database we store our data in Kafka and over the series look at some of the issues with this approach and how you can solve them. If you want to read from the beginning, you can find Part 1 here.
In Part 3 we introduced consumer groups and ran our application in multiple instances. This caused a major issue, our users would be distributed across the instances and the client requests could query a user that is not available on that instance. In this post we solve this issue and ensure the client can ask any instance for any existing user.
The problem we run into when we distribute our state across several instances is illustrated in this diagram from part 3. In this example if the client where to request any user partitioned on either partition 2 or 4 it would not get a 404 response.
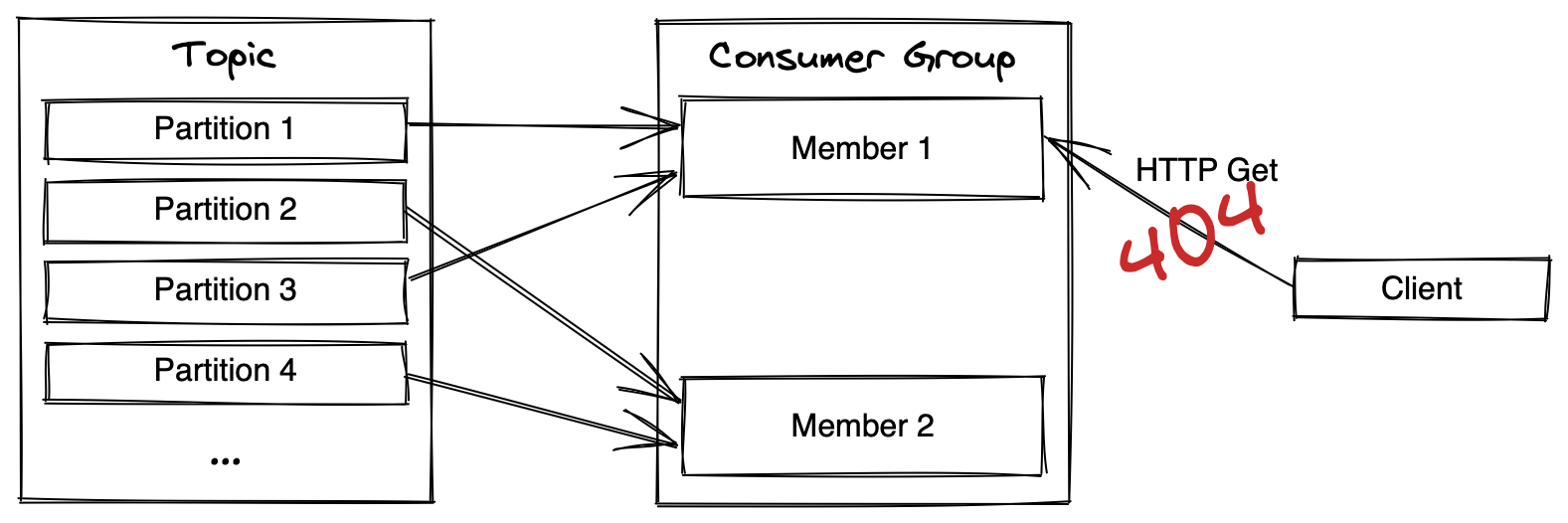
There are different ways we could approach this problem. We will solve this by proxying a request that arrives on the wrong instance to the correct one.
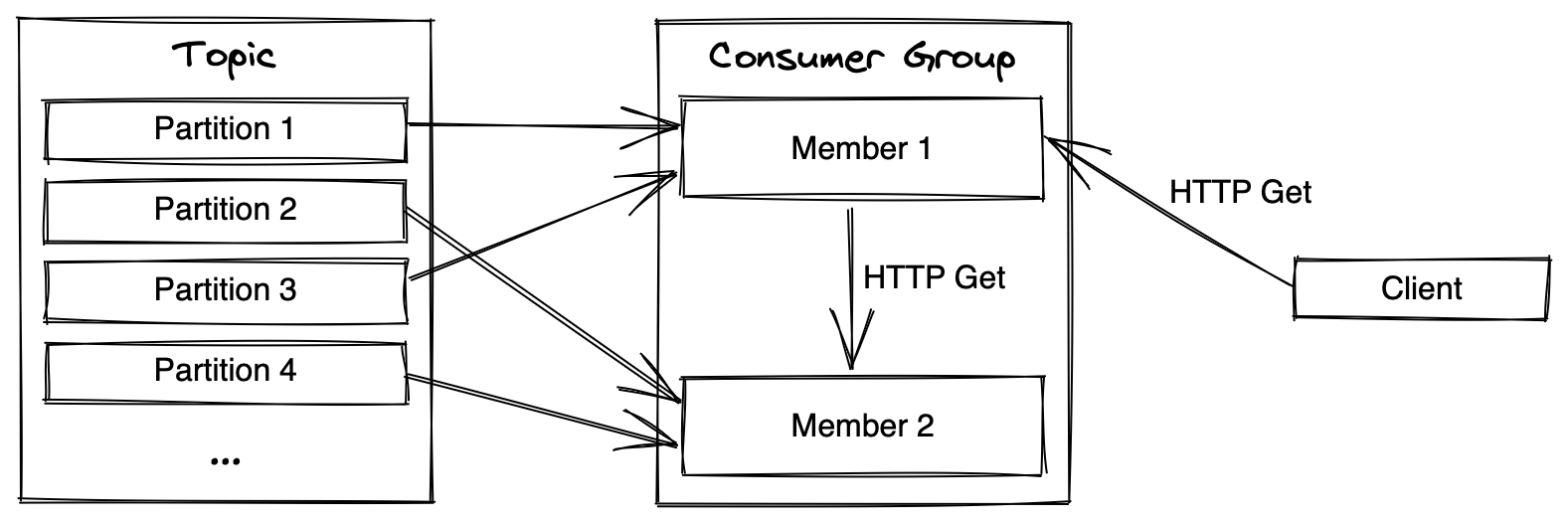
One could also imagine a ‘consumer group aware’ load-balancer sitting infront of all our instances and routing to the correct instance there, but I suspect that would be more complicated to implement.
In order for Member 1 in the illustration above to be able to proxy the client request to the correct member (Member 2 in the illustration) it needs to know which partitions each member in the group is assigned during the rebalance. To do this we can query Kafka for the consumer group metadata. In addition to knowing which instance is assigned which partition we also need to know the address of the HTTP api for that given instance.
We can add this to the consumer group metadata when the member joins the group. To do this we need to create a custom rebalancer which injects this in the join request. Writing our own rebalancer from scratch is a whole blog serie on its own so we are going to piggyback on one already implemented by the franz-go library we are using. There are several different rebalance implementations we could chose from, we keep it simple and go for kgo.RangeBalancer which is a fairly basic rebalancer.
type rangeBalancer struct {
kgo.GroupBalancer
rpcEndpoint string
}
func NewRangeBalancer(rpcEndpoint string) kgo.GroupBalancer {
return &rangeBalancer{GroupBalancer: kgo.RangeBalancer(), rpcEndpoint: rpcEndpoint}
}
func (r *rangeBalancer) JoinGroupMetadata(interests []string, _ map[string][]int32, _ int32) []byte {
meta := kmsg.NewConsumerMemberMetadata()
meta.Version = 0
meta.Topics = interests
meta.UserData = []byte(r.rpcEndpoint)
return meta.AppendTo([]byte{})
}
The kgo.RangeBalancer does not use the UserData field so we can easily inject our own data in that field. Some more advanced rebalancers (kgo.CooperativeStickyBalancer for example) use that field to keep state, for example to try and keep partitions assigned to the same group members across rebalances if possible. Such a rebalancer would actually be preferred in our use-case since it would make it possible to avoid re-consuming the whole history if the member is assigned the same instance it had before a rebalance. If you want to use one of those you likely need to wrap and unwrap that data so that the rebalancer still works.
Next we need to configure our Kafka client to use this rebalancer.
cl, err := kgo.NewClient(
...
kgo.Balancers(NewRangeBalancer(listenAddr)),
...
}
In addition to adding this information to the Metadata we also need to fetch it. We can use a DescribeGroup request to get this information from Kafka and then build a table where we can look up the UserData for a specific topic and partition.
func fetchGroup(ctx context.Context, group string, kClient *kgo.Client) map[string]string {
members := map[string]string{}
resp := kClient.RequestSharded(ctx, &kmsg.DescribeGroupsRequest{Groups: []string{group}})
for _, m := range resp[0].Resp.(*kmsg.DescribeGroupsResponse).Groups[0].Members {
metadata := kmsg.ConsumerMemberMetadata{}
metadata.ReadFrom(m.ProtocolMetadata)
assign := kmsg.ConsumerMemberAssignment{}
assign.ReadFrom(m.MemberAssignment)
for _, owned := range assign.Topics {
for _, p := range owned.Partitions {
members[owned.Topic+"-"+strconv.Itoa(int(p))] = string(metadata.UserData)
}
}
}
return members
}
To verify this let’s expose this information on a HTTP endpoint,
mux.HandleFunc("/groupinfo", func(w http.ResponseWriter, r *http.Request) {
m := fetchGroup(r.Context(), group, kClient)
b, _ := json.Marshal(m)
w.Write(b)
return
})
Running two instances of our application and querying this new endpoint we should get the same information from both instances,
$ curl "localhost:8080/groupinfo"
{
"user-0": ":8081",
"user-1": ":8081",
"user-2": ":8081",
"user-3": ":8081",
"user-4": ":8081",
"user-5": ":8080",
"user-6": ":8080",
"user-7": ":8080",
"user-8": ":8080",
"user-9": ":8080"
}
As you can see the address’ do not contain the hostname, that is because I have not been including it in the listen addr parameter when I start the application. From now on we need to do that, let’s update the default as well to make this more clear,
flag.StringVar(&listenAddr, "l", "localhost:8080", "HTTP listen port")
We could also get the hostname if none was provided by using os.Hostname for example.
Next up we need to update our HTTP Get handler to proxy the call to the correct instance if required, the first thing we need is a way to figure out which partition a specific key belongs to. We can do this by using the same partitioning code franz-go uses when producing messages, so let’s create a partitioner we can use at the top of our serveHttp-function.
func serveHttp(addr string, users *UserStore, kClient *kgo.Client, group string) func(ctx context.Context) error {
partitioner := kgo.StickyKeyPartitioner(nil)
mux := http.NewServeMux()
...
This allows us to add the proxying at the beginning of our Get-branch of the switch r.Method statement we have,
case http.MethodGet:
table := fetchGroup(r.Context(), group, kClient)
p := partitioner.ForTopic("user").Partition(&kgo.Record{Key: []byte(email)}, len(table))
if a, ok := table["user-"+strconv.Itoa(p)]; ok {
// if this instance is not assigned the partition we forward the request
if a != addr {
resp, err := http.Get("http://" + a + r.URL.String())
if err != nil {
fmt.Printf("failed to chain call to instance %s: %s", a, err)
http.Error(w, "Internal server error", http.StatusInternalServerError)
return
}
fmt.Printf("chain call: url=%s\n", resp.Request.URL)
io.Copy(w, resp.Body)
return
}
} else {
http.Error(w, "partition not found in routing table", http.StatusInternalServerError)
return
}
...
You should now be able to run a whole bunch of instances (up to ten, or whatever your partition count on the user topic is), each on different ports, use the Post endpoint to create a number of users, and finally be able to query the Get endpoint on any instance and always get the correct user returned.
As some of you may have noticed, we currently run the fetchGroup call for every HTTP request, this slows our application down and puts load on the Kafka cluster. We only need to update this routing table once after a consumer group rebalance, since it will never change in between rebalances, luckily franz-go provides a callback which is run after a rebalance. The following can be added as an option to kgo.Client,
kgo.OnPartitionsAssigned(func(ctx context.Context, c *kgo.Client, m map[string][]int32) {
fmt.Println("OnPartitionsAssigned")
}),
Here you could use fetchGroup and store the routing table and then use it in the HTTP handler. Remember to protect it with a sync.RWMutex since it may get accessed at any time, even during a rebalance, from the the HTTP code.
There is also a critical point after a consumer group rebalance has happened and the consumer is reading in the state to our map. During this time, until the consumer has caught up with the events on its’ assigned partitions, the state of the application is not yet synchronized and HTTP requests for users may end up with a ‘not found’ response. Our consume loop gets the HighWatermark for each partition it consumes, so it should be a fairly simple task to check if the application has caught up yet or not. Perhaps we will look into making all incoming HTTP Get requests wait for the application to catch up before we try to issue a response in a future post.
Over these four posts we have created a basic application that approaches some of problems you face when working with Kafka. We have implemented a CRUD application which might normally be backed by a more traditional datastore, but instead our state is persisted on Kafka. We have also made it possible to scale this application horizontally and split up the load between multiple instances.
As usual, the full source is available at github.